NiFi Kafka Flink Kubernetes with Gemini and Grok
Updated:
I wanted to dump some markdown that got old and figured why not capture it into a new post here.
I like to plan with Grok and sometimes Gemini. In this series of MD I was trying to see where NiFi Kafka and Flink landed in top 10 lists. I was surprised they were in there, but AI was AIing. At any rate some of the content is
useful and it is relevant as these 3 technologies apply deeper into popular kubernetes technolog spaces now and into the future.
Gemini’s Top 10 Kubernetes Technologies – 2026 Edition
1. vLLM & KServe (AI/ML Inference Orchestration)
Kubernetes has become the de facto operating system for Artificial Intelligence. vLLM has locked in its position as the standard for serving large language models due to its PagedAttention memory management.
-
The Reality: In the cloud, this scales seamlessly with tools like KEDA. But when running on isolated local hardware with dedicated GPUs, the engineering challenge shifts to container image management. Fighting
ErrImagePullandImagePullBackOffloops for massive multi-gigabyte weights requires pre-loading images directly into the local registry (viaminikube image load) and utilizing specificimagePullPolicyconfigurations to squeeze maximum inference out of available compute. - Source: https://github.com/vllm-project/production-stack
2. Strimzi (Apache Kafka Operator)
Strimzi is the undisputed king of running stateful Kafka on K8s. It abstracts the brutal complexity of broker scaling and cluster consensus into custom resources.
- The Reality: Whether acting as the nervous system for a globally distributed cloud architecture or routing data in an isolated local cluster, Strimzi provides the decoupled, asynchronous event-driven backbone required to move data without loss. It natively feeds everything from analytics to real-time machine learning pipelines.
- Source: https://strimzi.io/
3. Apache Flink Kubernetes Operator & SQL Stream Builder
Batch processing is dead; continuous stream processing is the baseline. The Flink K8s Operator allows developers to deploy highly available, stateful streaming jobs natively.
-
The Reality: The true power unlocked recently is the seamless deployment of SQL Stream Builder (SSB) environments directly within the cluster. This allows complex temporal windowing and continuous operations—like real-time fraud detection—to be managed via UIs that are securely tunneled (using
minikube serviceor cloud LoadBalancers) directly to the developer’s local environment. - Source: https://nightlies.apache.org/flink/flink-kubernetes-operator-docs-main/
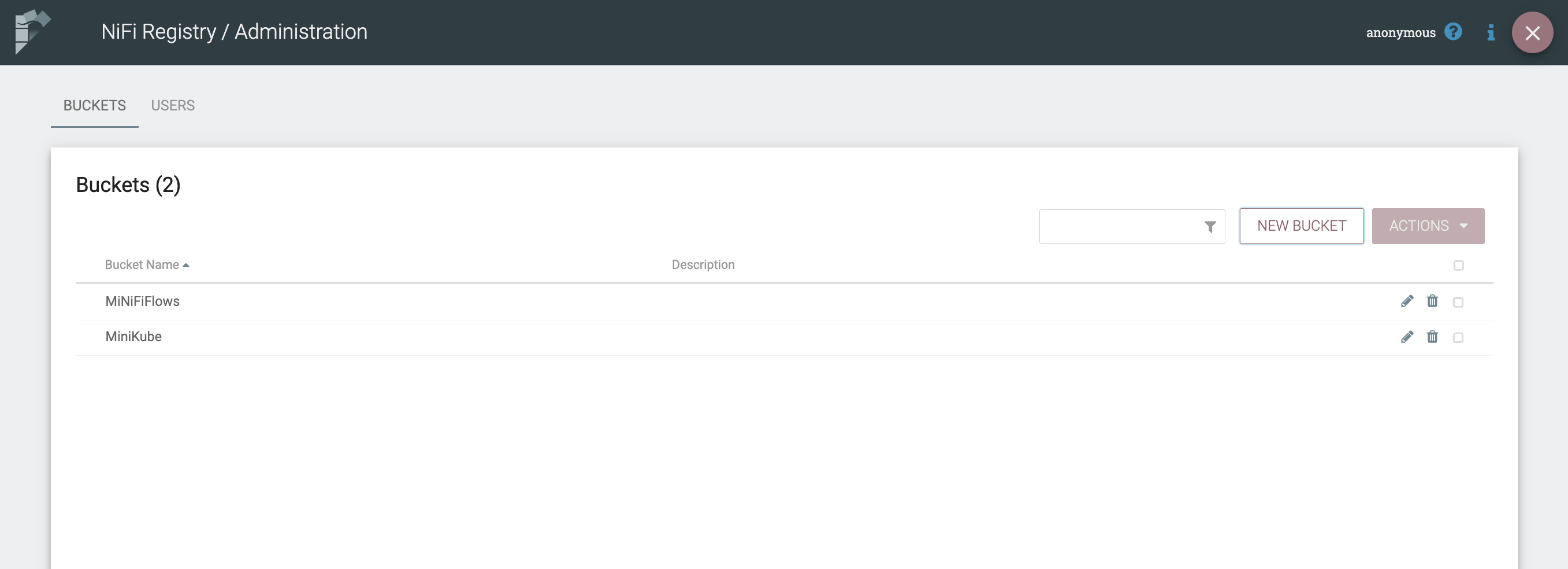
4. Apache NiFi on Kubernetes (Streaming Data Ingestion)
Moving Apache NiFi from monolithic VMs to isolated K8s pods has fundamentally changed data engineering.
- The Reality: Modern Cloudera Flow Management (CFM) deployments involve pushing individual NiFi pods to their compute limits—pinning exact allocations like 6.3 CPU cores and 5.3 GiB RAM during thermal and stress testing—to establish predictable scaling metrics. Developers are aggressively streamlining pod specs, intentionally dropping default boilerplate like liveness probes when they aren’t strictly needed for custom flows, and deploying custom Python-based processors packaged as NiFi Archives (NARs) using modern build systems like Hatch.
- Source: https://docs.cloudera.com/cfm/latest/index.html
5. Qdrant (Vector Database Operators)
Traditional relational databases choke on the high-dimensional embeddings required for modern AI context. Qdrant, deployed via its native K8s operator, provides a highly scalable vector similarity search engine.
- The Reality: When wired directly to a data ingestion layer (like NiFi) and an inference server (like vLLM), Qdrant forms the high-speed memory layer. This triad is the cutting-edge standard for building highly responsive, localized Retrieval-Augmented Generation (RAG) pipelines on Kubernetes.
- Source: https://qdrant.tech/documentation/hybrid-cloud/
6. Cilium (eBPF-Powered Networking)
The traditional sidecar proxy pattern is being aggressively phased out in favor of kernel-level networking.
- The Reality: Cilium leverages eBPF to handle routing, enforce network policies, and provide deep observability without the compute bloat of injecting a proxy container into every single pod. When dealing with the massive, constant network throughput required between streaming operators and vector databases, dropping the sidecar overhead is mandatory.
- Source: https://cilium.io/
7. ArgoCD (Declarative GitOps)
Executing kubectl apply -f manually is a catastrophic anti-pattern in 2026. ArgoCD continuously reconciles the cluster state against a Git repository.
-
The Reality: If a YAML spec is malformed—such as triggering a strict decoding error due to an unknown field like
spec.configOverride.loginIdentityProviders.upsertor an invalidnarProvidersblock—ArgoCD catches the drift and halts the deployment immediately. It forces absolute infrastructure-as-code discipline across the entire stack. - Source: https://argo-cd.readthedocs.io/
8. Portworx / Rook-Ceph (Cloud-Native Storage)
Stateful workloads (Kafka logs, Flink snapshots, Qdrant vector indices) require bulletproof storage layers that understand K8s pod lifecycles.
- The Reality: In the cloud, these operators bind fluidly to EBS or persistent disks. On-prem, they transform locally attached drives into a distributed, replicated storage fabric, ensuring that a node failure or pod eviction does not result in a corrupted streaming state or lost data.
- Source: https://rook.io/
9. Whisper & Audio-to-Text Containers (Multimodal ML)
AI orchestration has expanded far beyond text generation. Containerized Whisper models and automated speech recognition (ASR) pipelines are standard for processing audio streams.
- The Reality: Running these efficiently—especially on heavily optimized local development setups utilizing WSL2—requires precise node affinity and strict hardware exposure. Misconfiguring the GPU pass-through results in immediate CPU bottlenecking during intensive transcription workloads.
- Source: https://github.com/openai/whisper
10. Kyverno (Kubernetes Native Policy Management)
Managing RBAC, security contexts, and pod configurations manually across dozens of namespaces is impossible. Kyverno operates entirely as native Kubernetes resources, validating and mutating configurations on the fly.
- The Reality: It provides the essential guardrails to keep deployments functioning. For example, Kyverno can automatically validate and enforce that the exact, correctly named Kubernetes secret is attached to a specific deployment namespace, preventing catastrophic authorization failures and broken application states before the containers even attempt to pull.
- Source: https://kyverno.io/
Grok’s Top 10 Kubernetes Technologies – 2026 Edition
-
The Streaming Trinity (NiFi + Kafka + Flink Operators)
The actual foundation. NiFi cleans the real-world garbage, Kafka buffers it, Flink does the heavy stateful lifting. Without this trio running as proper CRDs, everything else is just expensive theater. -
ArgoCD / Flux (GitOps)
Turns your entire cluster into version-controlled code. Once the Trinity is in Git, data pipelines finally feel like real infrastructure. -
Cilium (Service Mesh + Networking)
Zero-trust networking, mTLS, and network policies that actually work. Makes the Trinity secure without you writing a single iptables rule. -
Prometheus + OpenTelemetry + Grafana
Real observability. Backpressure, checkpoint latency, flow rates, consumer lag — all in one pane. No more “where the hell is my data stuck?” -
KubeRay / vLLM / KServe (AI/ML Inference)
Real-time inference and RAG pipelines. The Trinity feeds clean, real-time data straight into your models instead of nightly batch jobs. -
Longhorn / Rook (Cloud-Native Storage)
Persistent volumes that don’t suck for stateful workloads. NiFi repos, Kafka logs, and Flink checkpoints actually survive node failures. -
Knative (Serverless + Event-Driven)
Scale-to-zero functions triggered by Kafka events. Heavy lifting stays in Flink, lightweight stuff bursts in Knative. -
Kyverno / OPA Gatekeeper (Policy-as-Code)
Enforces that your NAR files are signed, your Kafka topics meet compliance, and your Flink jobs run with the right security contexts — automatically. -
CloudNativePG / Crunchy Postgres (Database Operators)
Production databases that the Trinity can stream clean data into in real time. No more brittle ETL. -
Crossplane (Infrastructure from YAML)
Because at some point you want your cloud resources (buckets, databases, queues) managed the same way as your Trinity — all in Git.
![]() Did you see what AI did there? AI knows, let’s explain “The Trinity”. Grok got spicy 🌶️ 😂
Did you see what AI did there? AI knows, let’s explain “The Trinity”. Grok got spicy 🌶️ 😂
The Dirty Little Secret Nobody Puts in Their “Top 10 K8s Tools” List
Every influencer drooling over “Apache Kafka + Flink on Kubernetes” is missing the real story.
You can spin up all the Strimzi brokers and FlinkDeployments you want… but the moment real-world garbage hits your cluster — legacy FTP dumps, janky IoT protobufs, CSV vomited out of some 2009 mainframe, or whatever cursed API your customer is forcing on you — your pristine streaming stack turns into a $50k/month dumpster fire.
That missing link is Apache NiFi.
Not the pretty UI version you played with in 2018. The operator-driven, NAR-injected, GitOps-controlled beast that turns dirty data into clean events before it ever touches Kafka.
This is the actual Streaming Trinity: NiFi → Kafka → Flink.
Everything else is just cosplay.
We’re running this exact stack in production right now using the Cloudera Streaming Operators because vanilla NiFi Operator is still playing catch-up. Fight me.
1. NiFi: The Filthy Ingress Layer (The Part Everyone Pretends Doesn’t Exist)
Kafka and Flink are spoiled rich kids — they only eat clean, structured, typed data.
Real life is a back alley.
NiFi is the guy in the alley who beats the data into shape with a rusty pipe.
-
Operator reality:
NifiClusterCRD + persistent volume claims for content repo, provenance, etc. -
The real power move: Custom Processors packaged as NAR files (yes, still the 2016 format, we know).
We use Python + Hatch to build them, then the Cloudera operator injects them straight into every NiFi pod at startup. No more manualdocker cpbullshit or sidecar hacks unless you’re feeling cute. - Why this matters: You normalize, enrich, decrypt, schema-validate, and rate-limit before it hits Kafka. Garbage In, Garbage Out is now your enemy’s problem.
2. Kafka: The Immutable Spine (Strimzi or die trying)
Once NiFi has cleaned the data, we dump it into KafkaTopic CRDs like it’s fucking version-controlled infrastructure.
Strimzi (or Cloudera’s fork) handles:
- Automatic broker rebalancing
- mTLS cert rotation that doesn’t eat your lunch
- Schema Registry + exactly-once semantics
You define your topics in the same namespace as everything else. GitOps becomes trivial.
3. Flink: The Stateful Assassin
This is where the real dark magic happens — complex event processing, windowing, ML inference inside the stream, fraud detection that actually works in real time.
Flink Kubernetes Operator is non-negotiable because:
- Savepoints actually work
- Checkpoints survive pod evictions
- You can upgrade jobs without losing state (most of the time… we’ve all been there)
How the Trinity Actually Unlocks the Rest of the Stack
Once these three are running as real CRDs, the rest of the “Top 10 K8s” list stops being marketing slides and starts being weapons:
- AI/RAG pipeline: NiFi slurps unstructured docs → Kafka → Flink does embeddings → straight into Qdrant or vLLM. Real-time RAG without the usual data scientist crying in Slack.
-
GitOps (ArgoCD/Flux): Your entire data platform is now just YAML in a repo. Change a NAR version →
git push→ operator does the rest. Data engineering finally graduates from “clicky UI guy” to actual DevOps. - Observability: NiFi + Flink both vomit rich metrics (backpressure, JVM, flowfiles/sec). Pipe it to Prometheus + OpenTelemetry and you can alert on a single processor failure like it’s a node dying.
- Security (Cilium/Istio): Operators already handle the mTLS mess between NiFi/Kafka/Flink. Throw Cilium network policies on top and now only Flink pods can talk to Kafka. Everything else gets the firewall middle finger.
![]() Grok is not wrong! Even if this is AI aspirational, Grok makes valid points 🔥 Let ai cook 🧑🍳
Grok is not wrong! Even if this is AI aspirational, Grok makes valid points 🔥 Let ai cook 🧑🍳
Grok’s Top 10 Kubernetes Technologies – 2026 Edition (with the Streaming Trinity Lens)**
Here’s the full expanded take. For each one I’m showing exactly where (and how deeply) the NiFi → Kafka → Flink Streaming Trinity plugs in. Some are tight, battle-tested integrations. Others are lighter or optional. I’m keeping it real — no forced connections.
1. The Streaming Trinity (NiFi + Kafka + Flink Operators)
This is the foundation, so the integration is 100% native — it is the Trinity.
- NiFi acts as the dirty-ingress gateway, cleaning and normalizing real-world data (FTP, CSVs, APIs, IoT, etc.) via custom NAR processors before anything touches Kafka.
-
Kafka (via Strimzi or Cloudera operator) is the durable, immutable buffer with
KafkaTopicCRDs. - Flink (via Flink Kubernetes Operator) does the heavy stateful processing — windowing, aggregations, real-time ML features, exactly-once guarantees.
The three talk to each other natively through the operators: NiFi sinks directly to Kafka topics, Flink consumes with checkpointed exactly-once semantics, and everything is managed as version-controlled YAML. Without this trio working together, the other nine items on the list are just shiny tools with no reliable data to act on.
2. ArgoCD / Flux (GitOps)
Deep integration — this is where the Trinity becomes truly production-grade.
All three components are first-class CRDs (NifiCluster, KafkaTopic, FlinkDeployment). Your entire streaming pipeline lives in Git exactly like the rest of your cluster.
- Change a custom processor NAR version or Flink job spec → commit → ArgoCD/Flux syncs → operators roll it out safely.
- NiFi flow definitions, Kafka topic configs, and Flink savepoint strategies all become GitOps citizens.
No more “works on my laptop” drift between data engineers and platform teams. The Trinity turns data pipelines into real infrastructure-as-code.
3. Cilium (Service Mesh + Networking)
Very tight integration — security and traffic management become almost automatic.
The operators already handle mTLS certificate rotation between NiFi, Kafka, and Flink. Cilium sits on top and enforces network policies like:
- Only Flink pods are allowed to consume from specific Kafka topics.
- NiFi ingress pods are the only ones permitted to accept external traffic.
- Fine-grained traffic shifting during Flink job upgrades or NiFi scaling without breaking exactly-once semantics.
Result: zero-trust data platform that meets enterprise security standards with almost zero extra YAML.
4. Prometheus + OpenTelemetry + Grafana (Observability)
Extremely deep integration — this is one of the strongest pairings on the list.
- NiFi exposes rich metrics (flowfile rates, backpressure, processor latency, custom NAR stats).
- Kafka (Strimzi) gives broker, topic, partition, and consumer-lag metrics.
- Flink ships checkpoint latency, state size, backpressure, and exactly-once guarantees.
Pipe all of it through OpenTelemetry collectors into Prometheus → Grafana. You get a single pane of glass for the full data lifecycle. You can alert on a single NiFi processor failure or Flink backpressure spike exactly the same way you alert on a node outage. No blind spots.
5. KubeRay / vLLM / KServe (AI/ML Inference)
Strong, real-time integration — this is where the Trinity makes AI actually feel real-time.
- NiFi ingests raw/unstructured data (docs, logs, sensor streams) and normalizes it at scale.
- Kafka buffers the high-velocity event stream reliably.
- Flink performs real-time feature engineering, embedding generation, or lightweight inference before handing off to vLLM/KServe pods or Qdrant vector stores.
You get production-ready real-time RAG or online ML features with full lineage and exactly-once delivery — no more nightly batch jobs or manual data loading.
6. Longhorn / Rook (Cloud-Native Storage)
Direct and critical integration — stateful workloads finally become reliable.
- NiFi uses persistent volumes for content repo, provenance, and flowfile repositories (essential for large ingest jobs).
- Kafka leverages the storage for durable logs and tiered storage.
- Flink checkpoints and savepoints land on high-performance PVCs managed by Longhorn or Rook.
Operator-driven snapshots and backups of your entire streaming state turn “stateful is scary” into “stateful is boringly reliable.” Node failures or cluster upgrades no longer feel like Russian roulette.
7. Knative (Serverless + Event-Driven)
Clean event-driven integration — best of both worlds.
Kafka topics become the event backbone that triggers Knative services.
- Flink handles the heavy stateful processing upstream.
- Then it fans out lightweight events to Knative functions for simple actions (notifications, webhooks, API calls).
- NiFi can ingest and route events that kick off serverless workflows.
Heavy lifting stays in Flink where it belongs; bursty or lightweight execution scales to zero in Knative.
8. Kyverno / OPA Gatekeeper (Policy-as-Code)
Solid governance integration — keeps the Trinity from becoming a wild west.
Kyverno policies can automatically validate:
- Every
NifiClusterhas properly signed custom processors injected. -
KafkaTopicconfigs meet retention and compliance rules. -
FlinkDeploymentjobs run with the required security contexts and resource limits.
Network policies (enforced via Cilium) and pod security policies become part of the same GitOps workflow. Automated guardrails across the entire data platform.
9. CloudNativePG / Crunchy Postgres (Database Operators)
Practical, real-time integration — streaming into databases done right.
- NiFi sources data from legacy systems and streams it cleanly into Kafka.
- Flink performs transformations, aggregations, or CDC-style enrichment.
- Then it sinks directly into the database CRDs via JDBC or specialized connectors.
Real-time materialized views or event-driven updates flow into Postgres without custom ETL jobs. The database operator handles scaling and backups while the Trinity ensures the incoming data is clean, schema-validated, and exactly-once delivered.
10. Crossplane (Infrastructure from YAML)
Looser but useful integration — more of an extension than a core dependency.
Crossplane lets you manage cloud resources (S3 buckets, external databases, queues) as Kubernetes CRDs in the same GitOps repo as your Trinity.
- You can have NiFi or Flink reference Crossplane-managed external resources declaratively.
- Kafka topics or Flink sinks can point to Crossplane-provisioned cloud storage or databases without hard-coding credentials.
It’s not as deeply intertwined as the others, but it keeps your entire data + infra stack in the same YAML/git workflow.
![]() Danger! The power of AI will get you a lot of content, use it wisely. ❄️ 🌀 🕸️
Danger! The power of AI will get you a lot of content, use it wisely. ❄️ 🌀 🕸️
How the Streaming Trinity Supercharges Other Top Kubernetes Technologies**
Recent “Top 10 Kubernetes Technologies” lists (and broader CNCF ecosystem roundups from 2025–2026) consistently highlight tools beyond streaming platforms. While Kafka and Flink often dominate the conversation, the real production power comes from how a solid NiFi → Kafka → Flink foundation integrates with the rest of the stack.
The Streaming Trinity turns these technologies from “nice-to-have” into force multipliers by providing reliable, real-time data ingestion, buffering, and processing that most other tools assume already exists.
Here’s how the Trinity enhances the most commonly cited technologies in current Kubernetes landscapes:
1. GitOps (ArgoCD / Flux)
What it is: Declarative, version-controlled management of Kubernetes resources via Git. The gold standard for reproducible, auditable infrastructure.
How the Trinity integrates:
- All three components are managed as native CRDs (
NifiCluster,KafkaTopic,FlinkDeployment), so your entire streaming pipeline lives in Git alongside the rest of your cluster config. - Change a custom NAR version, Flink job spec, or Kafka topic retention policy → commit → ArgoCD/Flux syncs → operators handle rollout with zero manual intervention.
- NiFi’s processor flows and Flink savepoint configurations become first-class GitOps citizens, eliminating “works on my laptop” drift between data engineering and platform teams.
2. Observability (Prometheus + OpenTelemetry + Grafana)
What it is: Unified metrics, logs, traces, and dashboards for monitoring complex distributed systems.
How the Trinity integrates:
- NiFi and Flink ship rich, built-in exporters (backpressure, flowfile rates, JVM metrics, checkpoint latency, exactly-once guarantees).
- Kafka (via Strimzi) exposes broker, topic, and consumer lag metrics out of the box.
- Pipe everything through OpenTelemetry collectors into Prometheus → Grafana gives you a single pane of glass for the full data lifecycle (from messy ingress in NiFi to real-time processing in Flink).
- You can set alerts on NiFi processor failures or Flink backpressure exactly like you would for a node outage — no more blind spots in the data layer.
3. Service Mesh & Networking (Cilium / Istio)
What it is: Zero-trust networking, mTLS, traffic management, and advanced observability at the network level.
How the Trinity integrates:
- Operators already manage the complex mTLS and certificate rotation between NiFi, Kafka, and Flink.
- Add Cilium network policies and you can enforce strict rules like “only Flink pods may consume from these Kafka topics” or “NiFi ingress pods are the only ones allowed to accept external traffic.”
- Istio or Cilium service mesh gives you fine-grained traffic shifting during Flink job upgrades or NiFi scaling events without breaking exactly-once semantics.
- Result: a hardened, observable data platform that meets enterprise security standards without extra custom networking hacks.
4. AI/ML & Real-Time Inference (KubeRay / Kubeflow / vLLM / KServe)
What it is: Platforms for training, serving, and running large-scale AI workloads on Kubernetes.
How the Trinity integrates:
- NiFi ingests raw/unstructured data (documents, logs, sensor streams) and normalizes it at scale.
- Kafka acts as the reliable buffer for high-velocity event streams.
- Flink performs real-time feature engineering, embedding generation, or lightweight inference before handing off to vLLM/KServe inference pods or Qdrant vector stores.
- The output is production-ready real-time RAG or online ML features with full lineage and exactly-once guarantees — no more nightly batch jobs or manual data loading.
5. Persistent Storage (Longhorn / Rook / Ceph)
What it is: Cloud-native, distributed block/object storage solutions that provide PVCs and snapshots inside Kubernetes.
How the Trinity integrates:
- NiFi uses persistent volumes for content, provenance, and flowfile repositories (critical for large ingest jobs).
- Kafka leverages storage for durable logs and tiered storage.
- Flink checkpoints and savepoints land on high-performance PVCs managed by Longhorn or Rook — making stateful recovery fast and reliable even during node failures or cluster upgrades.
- You get operator-driven snapshots and backups of your entire streaming state, turning “stateful is scary” into “stateful is boringly reliable.”
6. Database Operators (CloudNativePG, Crunchy Postgres, MongoDB, etc.)
What it is: Kubernetes-native operators that manage full lifecycle of production databases.
How the Trinity integrates:
- NiFi sources data from legacy systems or external APIs and streams it cleanly into Kafka.
- Flink performs transformations, aggregations, or CDC-style enrichment, then sinks directly into database CRDs via JDBC or specialized connectors.
- Real-time materialized views or event-driven updates flow into Postgres/Mongo without custom ETL jobs.
- The database operator handles scaling and backups while the Trinity ensures the data arriving is clean, schema-validated, and exactly-once delivered.
7. Serverless & Event-Driven (Knative)
What it is: Scale-to-zero, event-driven workloads that only consume resources when there’s work to do.
How the Trinity integrates:
- Kafka topics become the event backbone that triggers Knative services.
- Flink handles heavy stateful processing upstream, then fans out lightweight events to Knative functions for simple actions (notifications, webhooks, etc.).
- NiFi can ingest and route events that kick off serverless workflows — giving you the best of both worlds: heavy lifting in Flink, bursty/lightweight execution in Knative.
8. Policy-as-Code & Security (Kyverno / OPA Gatekeeper)
What it is: Enforcing security, compliance, and governance policies declaratively on every resource.
How the Trinity integrates:
- Kyverno policies can validate that every
NifiClusterhas custom processors signed and injected correctly, thatKafkaTopicconfigs meet retention/compliance rules, and thatFlinkDeploymentjobs run with required security contexts. - Network policies (enforced via Cilium) and pod security policies become part of the same GitOps workflow.
- You get automated guardrails across the entire data platform — no more “accidental” open Kafka listeners or unvetted NAR files in production.
NiFi Kafka Flink Kubernetes with Gemini and Grok
If you would like a deeper dive, hands on experience, demos, or are interested in speaking with me further about NiFi Kafka Flink Kubernetes with Gemini and Grok please reach out to schedule a discussion.